Code: https://github.com/Kevin-Jonaitis/orderly
Introduction and Goals
A few weeks ago I decided to build a locally runnable AI fast-food order taker. The project takes a menu image, lets a user order items conversationally, and returns an updated order with prices — all running on my GPU.
The purpose of this project was 3-fold: I wanted to work with the latest AI dev tools (Claude Code, Cursor), I wanted it to run locally, and I wanted it to have as low latency as possible. I also gave myself 2 weeks to finish it.
My inspiration was when I started hearing AI like Sesame AI and Unmute by Kyutai. If you haven’t tried these out, please, stop reading this, and go try them. They are INCREDIBLY uncanny in terms of voice, and real-time. They’re not like Alexa or Siri that sound robotic. These sound like REAL people — to the point that I feel bad hanging up on them without saying goodbye.
Vibe Coding
I vibe coded this whole project. I typed out maybe 200 lines of code myself; everything else was me telling Claude what to do.
Now, that’s not just to say I simply accepted whatever Claude wrote. I’d say only 5% of the original code Claude originally wrote ended up in the final product. Almost all of the code went through multiple versions of me telling Claude how to refactor it. So while my hands might not have typed out the keystrokes, I reviewed every line for clarity and functionality.
I think if Vibe coding isn’t in your toolbox already, you’re doing it wrong. For prototypes, vibe coding is unbeatable — you can get a proof of concept running fast, or test out ideas quickly. It’s also great for migrations: “transcribe this from Java to C++” or “move this from Linux to Windows” are now tasks worth reconsidering, because AI makes them far easier than before.
With Claude, I could break down step by step what I wanted to do, and iterate on that plan before even having it touch a line of code. Claude even has a dedicated “planning mode” to help with this. I feel like Claude’s dedication to building plans is what separated it from Cursor (while Cursor could also do this, it didn’t seem as much of a focus).
Here’s an example of a plan it generated for integrating a TTS model:
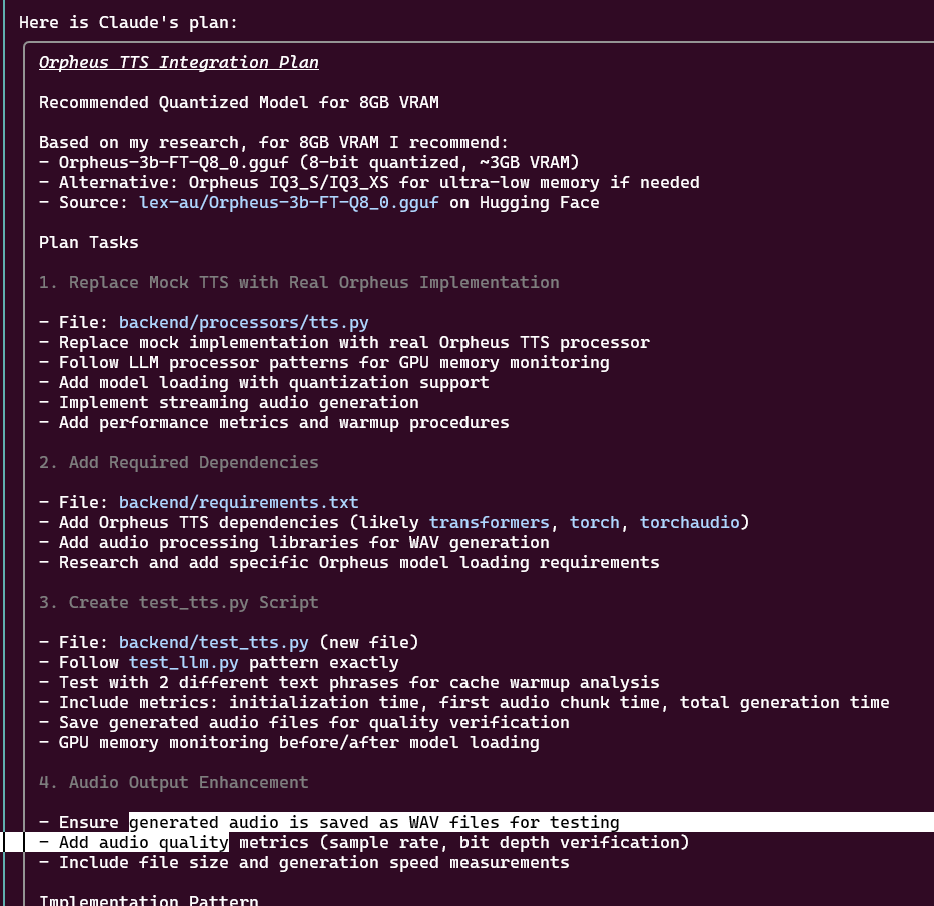
Even for UI work, AI is fantastic. It wrote a working UI in under a minute, and I could adjust layouts or components with simple prompts. With AI-first frameworks and component libraries, I think how we write code — especially prototypes — is going to be heavily disrupted.
Strategy
So going back to the strategy, this was my plan:
- Run a STT (speech to text), LLM, and TTS (text to speech) pipeline that could fit 100% on my GPU (originally a 3070 with 8GB of VRAM).
- To decrease latency, I was going to try and have the STT and LLM run in parallel — as soon as a word was ready from the STT, we’d send it to the LLM and start processing; if a new word came in, we’d cancel the old LLM inference request and start a new one. That way, we never had to have a 200–300 ms pause to detect that the user was done speaking before starting the LLM querying.
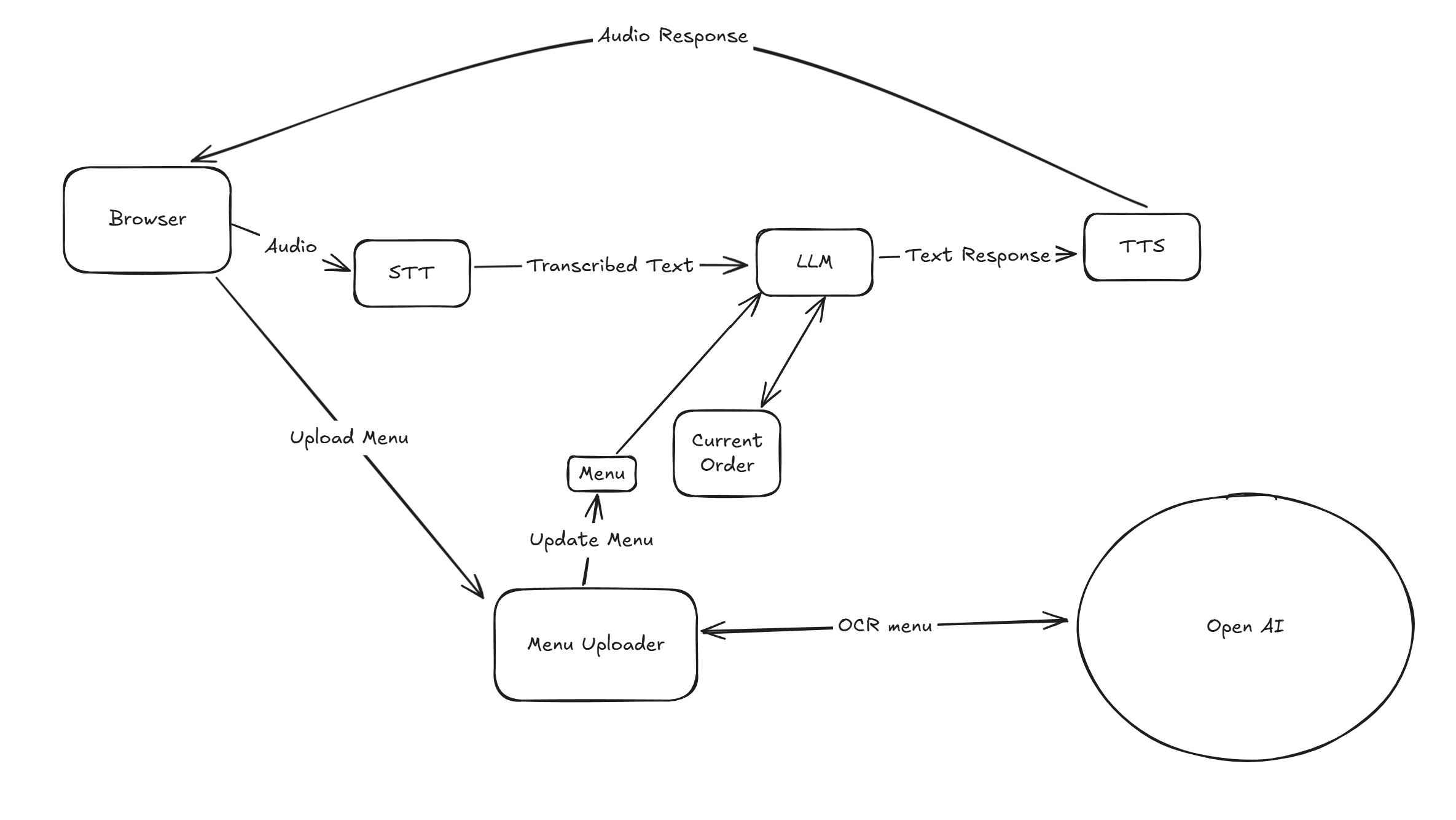
And here’s the architecture of it all:
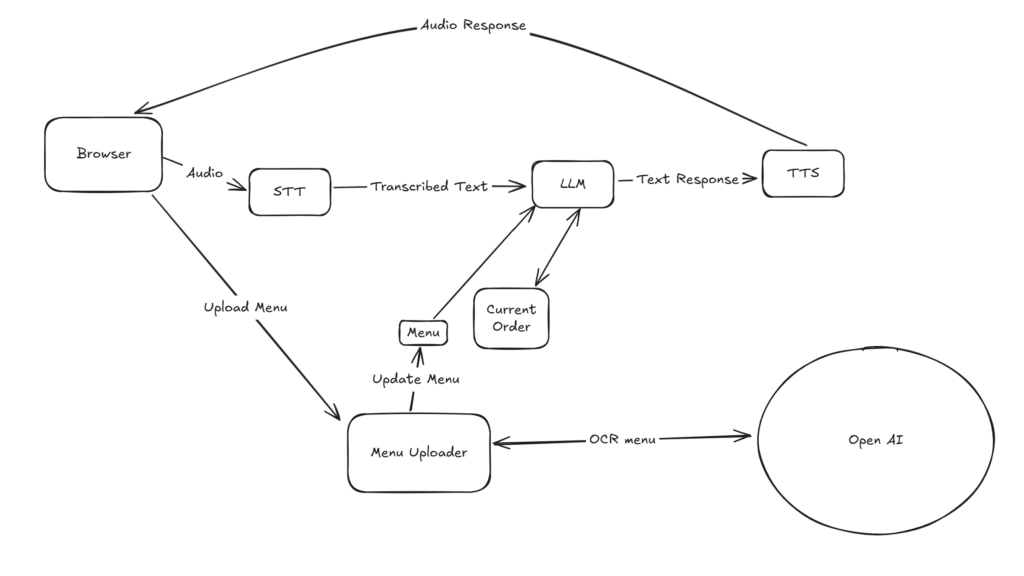
Streaming STT From Nvidia
I first looked at streaming STT from Nvidia, specifically NeMo FastConformer. Streaming means it can output words chunk by chunk as they’re spoken, instead of waiting for the whole sentence.
In practice, though, this wasn’t very useful. Time-to-first-word was real-time (<50 ms per word), but Whisper Lite could transcribe a full sentence in about the same time (50–100 ms). NeMo also required more VRAM (3–5 GB compared to Whisper’s 1–2 GB), and Whisper’s accuracy was simply better. So despite looking faster on paper, Whisper ended up being the better option. Sometimes what’s theoretically faster just isn’t in practice — and that’s why we test.
Model Choices
After deciding to stick with Whisper for STT, I still needed to balance the rest of the pipeline across my GPU. On my original 8GB 3070, I could only allocate 1–2 GB for STT/TTS and about 4GB for the LLM.
This worked…terribly. The biggest problem was the LLM: any LLM less than ~8 GB wasn’t really good at following instructions, no matter how many examples or rules I gave it.
The solution? Buy a bigger graphics card. I opted for a 5070 Ti with 16GB VRAM. With that higher roof, I landed on these specs:
- STT: Whisper Lite (~2 GB VRAM).
- LLM: Phi-3 Medium (~8 GB VRAM). Phi-3 Small didn’t follow instructions well.
- TTS: Orpheus (~2–3 GB VRAM) paired with SNAC (~1 GB VRAM).
Total VRAM usage: ~14 GB.
Structuring LLM Output for Faster Response
Another optimization was how I structured the LLM output. The LLM produced both conversational text and an updated order. Rather than wait for the entire response, I streamed the conversational text to TTS as soon as it appeared.
For example:
Okay, I’ve got your order: three tacos, one Crunchwrap, and one lemonade instead of a Coke. Does that look right?
Updated Order:
-3x Tacos
-1x Crunchwrap
-1x Lemonade
This shaved a few hundred milliseconds, since TTS could start speaking while the model was still outputting the updated order.
KV Caching + Prefix Caching
I also learned how much caching matters for latency. LLMs generate one token at a time, and without caching, each new token requires recomputing the entire prompt + history from scratch. KV caching fixes this by storing hidden key/value states for each token: once the model has read the context, each new token only needs to process the latest step.
That sped up streaming but consumed more VRAM. On top of that, there’s prefix caching. In my project, every request started with the same system prompt — the menu and rules of how the agent should behave. llama-cpp supports reusing that fixed prefix across multiple runs. Instead of re-encoding those 500+ instruction tokens every time, you can cache them once and “pin” them, then only add the user’s order on top.
This is where my warm-up run came in. At startup, I ran a tiny dummy inference, which warmed up both the KV cache and the prefix cache. This shaved hundreds of milliseconds off every request, getting me closer to that (hopefully) sub 1-second latency.
Concurrency Challenges
Some latency challenges weren’t about model choice at all, but about how Python handles concurrency. Python uses a Global Interpreter Lock (GIL), which means only one thread’s Python bytecode can execute at a time in a process — even if you have multiple threads.
My problem came up with llama-cpp-python, a Python port of llama.cpp. Its inference calls didn’t release the GIL, so while the model was generating tokens, my TTS code never got a chance to run. Instead of streaming audio as soon as the first sentence was ready, TTS sat idle until the model completely finished.
Switching to threads wouldn’t have fixed it, since all threads in Python share the same GIL. My solution was to move each AI component into its own process and use inter-process queues for communication. That eliminated GIL contention completely and let everything run smoothly.
And while these were problems inside my code, my environment and tools also started working against me.
Tooling Tradeoffs + Cursor
I was programming on Windows and wanted to give WSL (Windows Subsystem for Linux) a shot. It basically gives you a Linux environment within Windows, and most importantly, Claude Code only works on WSL.
Halfway through the project, I ran into issues sending audio between the browser and backend services. WSL and Windows had networking problems that made communication unreliable, and after hours of frustration, I decided the easier solution was to move the whole project to Windows.
That meant losing access to Claude Code. But failures sometimes present opportunities: moving to Windows gave me the chance to try out Cursor.
Cursor worked, but not without issues. The AI agent was buggy, often hanging when running commands, and its planning mode wasn’t as strong or verbose as Claude’s. It also felt like it had fewer tools available. Still, it let me keep momentum on the project and explore another approach to AI-assisted development — one that worked, but wasn’t quite as capable as Claude Code for deeper engineering tasks.
Efficient Prompt Engineering
One of the hardest parts of the project was getting the LLM to reliably update a user’s order from the menu. It hallucinated: sometimes adding items not on the menu, deleting items already in the order, or making false claims (“yes bread is gluten free”).
At first I kept adding more rules — I had a list of about 12 — but the biggest improvement came from examples. When I gave it short dialogues like “User said X → LLM responded Y,” and made sure each example covered a couple of rules, the model behaved much more reliably.
The lesson: examples trump rules. A small set of well-chosen examples worked orders of magnitude better than piling on instructions.
New Paradigms for Using AI
Here are two new ways I found myself using AI models during this project.
The first is brute-forcing solutions. This came when my audio decoding sounded wrong. I could hear human speech, but it was distorted beyond recognition. Instead of debugging the codecs by hand, I asked Claude to brute force it: generate different decoding methods, sample rates, and output WAV files. In less than 2 minutes I had 20 samples, listened to them, and picked the closest. Having AI brute force possibilities like this is a new paradigm — something that didn’t exist before, and now feels like part of our toolbox.
The second was about patterns. LLM models are great when you provide them a pattern to follow. Near the end of the project, I needed to use WebSocket for audio streaming. I found a project online doing something similar and simply pointed Claude at the code and told it to adapt those patterns into my code (disclaimer: I cited the original user and made sure the licensing was correct). It was essentially able to copy the patterns and integrate them seamlessly, even though the specifics of the use case weren’t the same.
Conclusion
In the end, I built a project that could, given a menu image, allow a user to order items off a menu: asking questions, making recommendations, handling ingredients, and producing an updated order with prices.
It ran 100% locally (besides OCR sent to OpenAI). Latency ended up around 1.5 seconds, not the <1 second target, due to GPU limits and model contention.
Still, it was a fun project in “how low can I get this latency given these constraints.” Just as importantly, it showed me the power of Claude Code and Cursor, and gave me firsthand experience using them as development tools.