This post is about the interesting ways I optimized my pathfinding algorithm – from 400ms for an average path to around 30ms – a 10x improvement. The decision making process on how I got to this improvement was pretty interesting, and required some insights into how programming languages work. So let’s dive in.
So, in a graph network, you may want to do pathfinding between nodes.
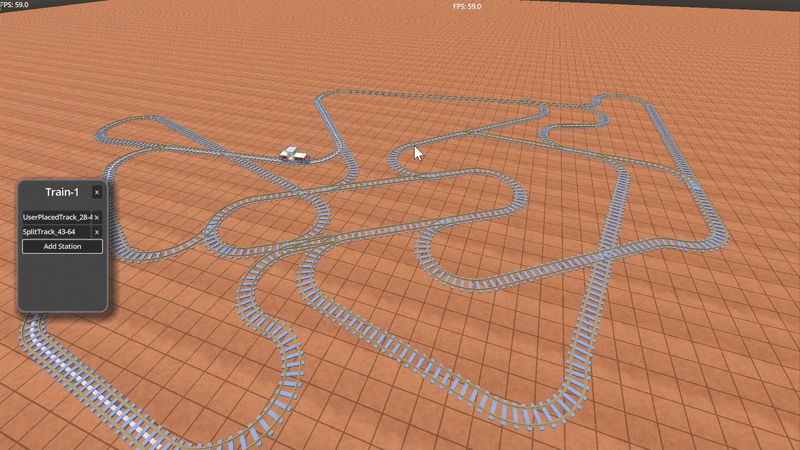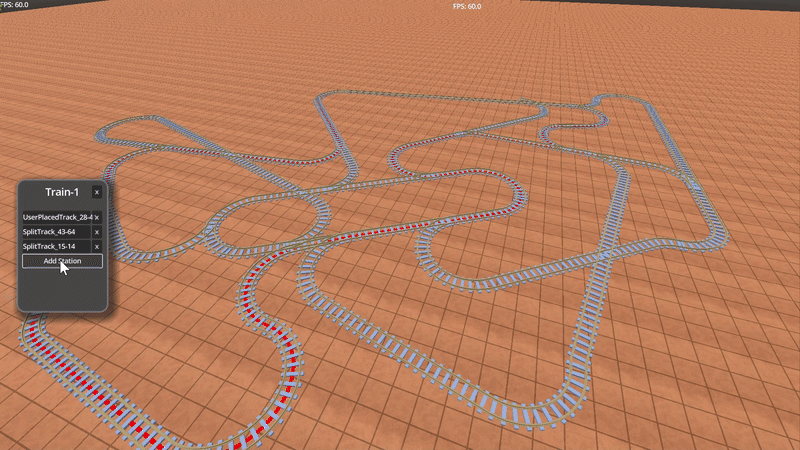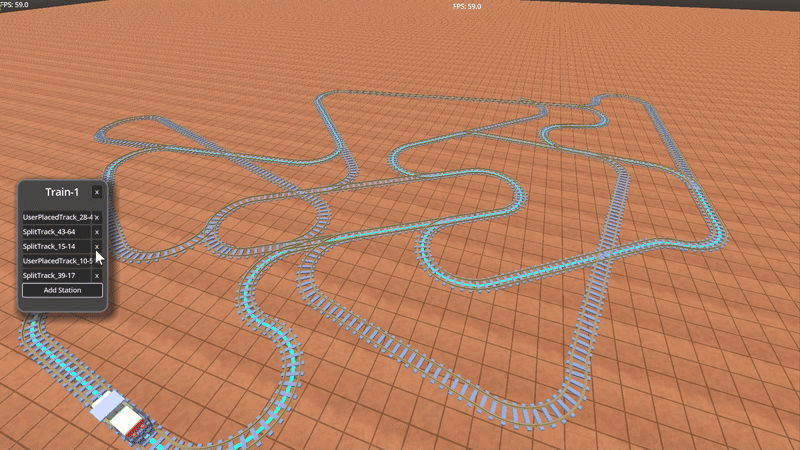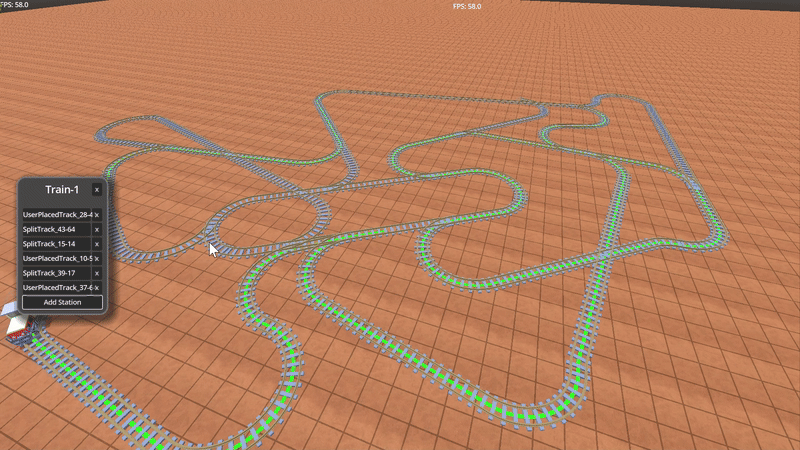
Above is an example of a train with multiple “stops” in a train network. The colored lines show the path between stops.
These train tracks are modeled using a directed graph with edges and nodes – you can read more about it HERE<INSERT LINK HERE>.
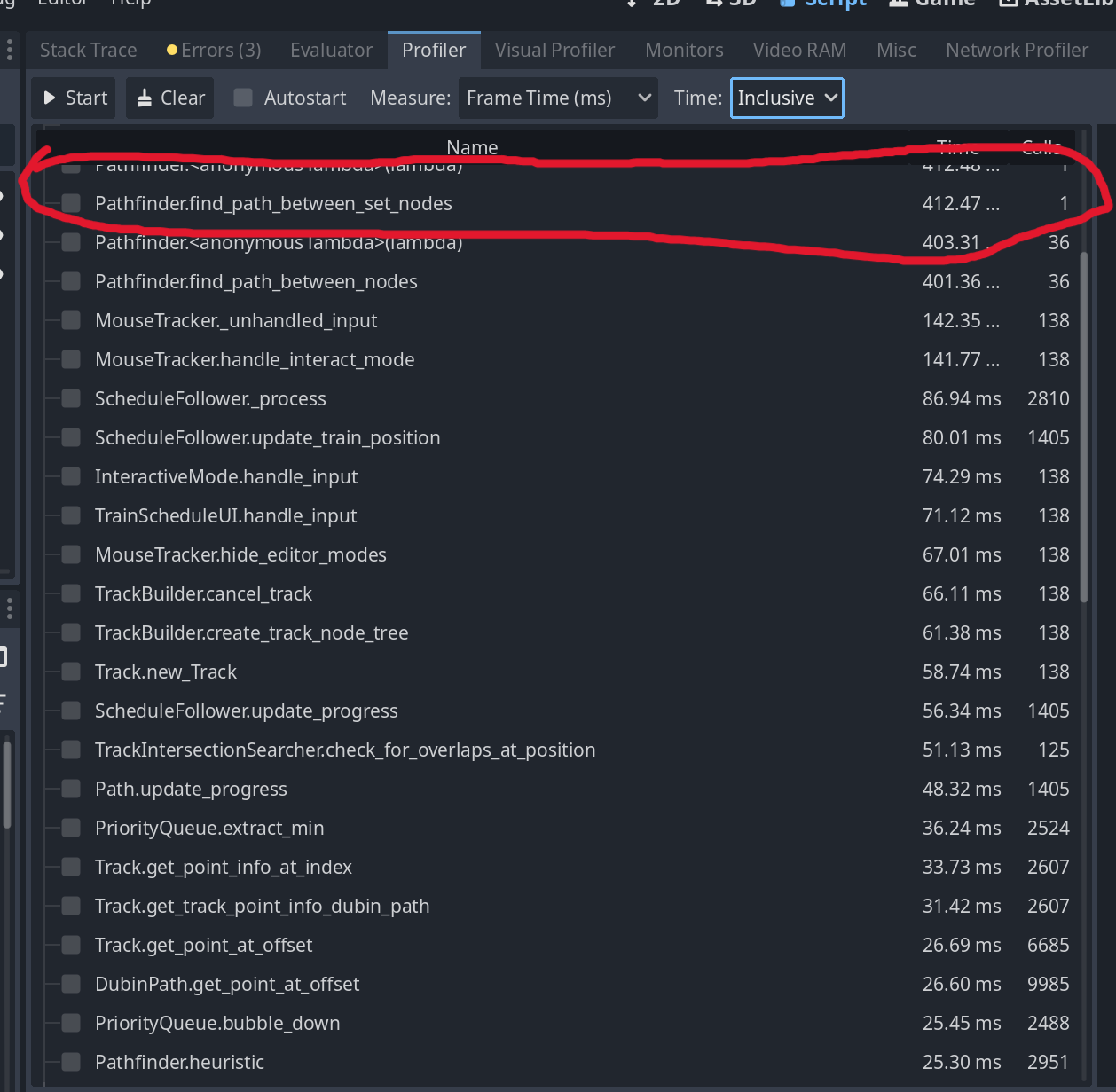
Essentially, I was running A* search algorithm across this graph to find a path between two stops. Here’s an example of the runtime of the algorithm, on a somewhat simple graph between 2 “STOPS”. You can see in the image below it takes about 400ms:
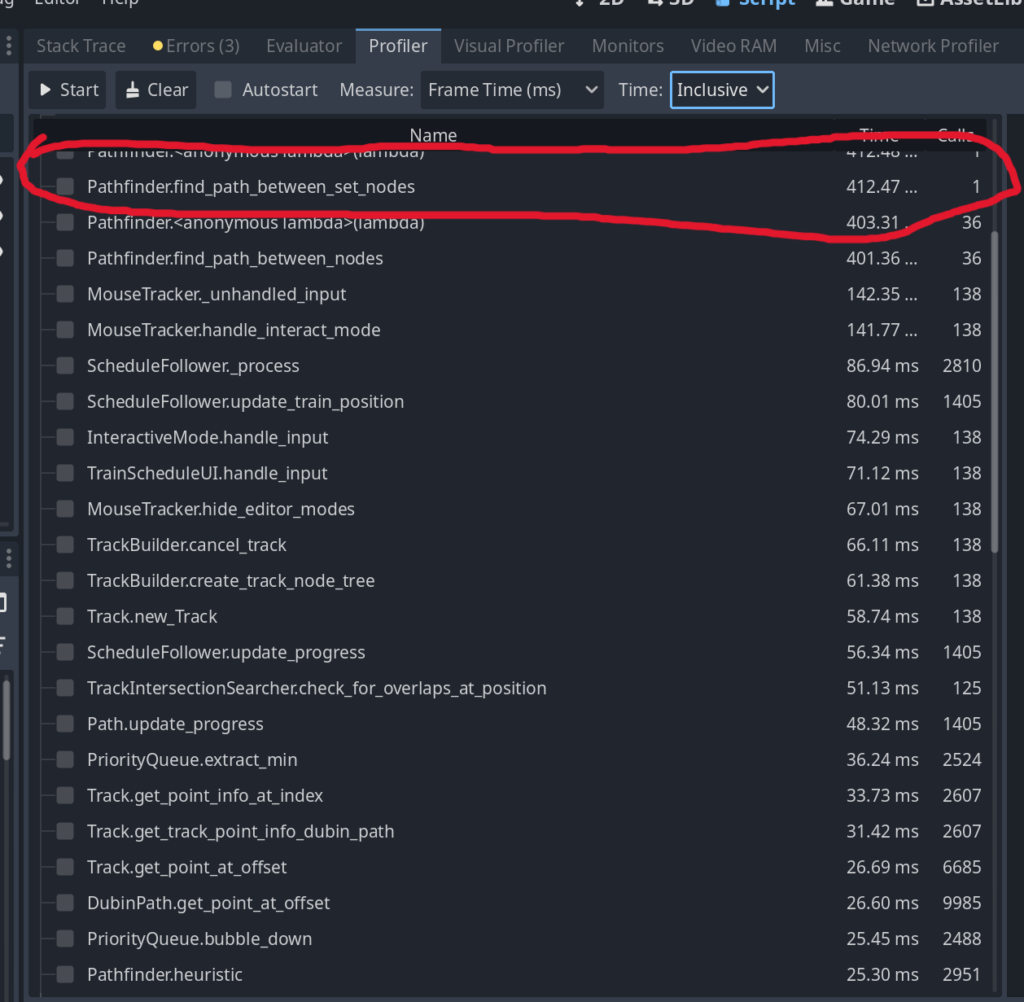
The highlighted part shows the pathfinding. That’s way too slow. Let’s dive in.
GDScript, C++, interpreted languages, call overhead
Now, the above code is written for a videogame I was building that was written in the godot game engine. The godot engine is written in C++ – you can write code for your game in multiple languages, but the main supported language is called “GDScript” which is an interpreted language. Interpreted languages, for those who don’t know, are essentially programming languages where the code you write is interpreted at runtime at a line-by-line basis by a VM into machine code that the computer(CPU) can read. Languages like this include python and javascript(to a degree).
As I mentioned, 400ms is much too slow for a simple pathfinding algorithm. We need to optimize it. When we think of optimizing our pathfinding algorithm, we have a couple of choices:
- Change our code in some way to be more optimal. This could be done by changing algorithms, changing our model, or optimizing or restructuring our code)
- Change our requirements(how paths work, limit size of network, cap search space, ect)
- Rewrite the whole pathfinding module in C++ and hope that it’s faster
- Be _percise_ and rewrite the parts of the project we know would benefit from a compiled language like C++
#3 is a naive approach – it essentially is “I don’t know why this is slow, but I’ve heard C++ is fast, so let me just write the whole project in C++ and hope for the best”. You and I are more discerning engineers than that, so we won’t take that approach.
Before we make any changes, let’s try and build a deeper understanding of what’s going on. Why is our code slow? If we look at the above call graph, we’ll see a few functions that are slow, but we know they can be theoretically really fast:
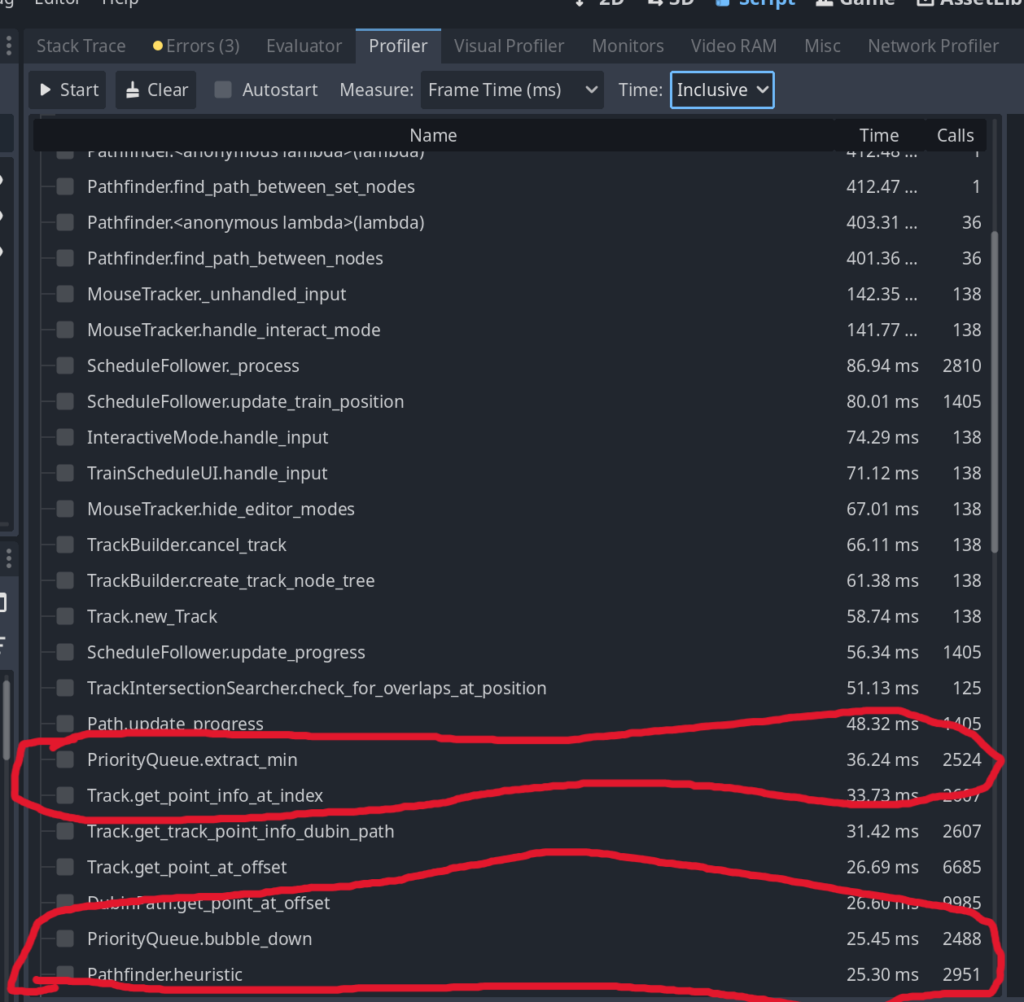
These three calls are slow, but they should be lightning fast: PriorityQueue.extract_min, PriorityQueue.bubble_down, Pathfinder.heuristic
The A* algorithm consistent of a priority queue and a heuristics algorithm. You use the heuristic algorithm to determine which edges you should “check” next for the shortest path between your start and end nodes, and then throw them in a priority queue; you then pull things off the priority queue in terms of lowest estimated cost to your end node and repeat the checking process until you hit your end node. You can read more about A* here: https://en.wikipedia.org/wiki/A*_search_algorithm
Now, priority queues should be fast. This is a fundamental data structure that isn’t that complicated, and is well studied in computer science. In the above, if you crunch the number of calls / the time it took to run, you can see that it takes about 0.01ms, or 10,000 ns to pull an item off of the queue. Realistically, pulling things off a queue should only take a handful of instructions; my intuition says this is way too slow for what it should be; I only have a few thousand things that go through my queue, so pulling them on/of should be on the order of ns, not 10s of ms. If you’re less familiar with timings of things(or want to build your intuition), I suggest looking up lists like peter norvig’s list of approximate timings of things on a computer:
http://norvig.com/21-days.html#answers. As you get deeper in your career, you’ll have a good intuition for how long algorithms and data structures should be for your language and architecture you’re running on.
In any case, we can see these priority queues and heuristics are taking way longer than what we can get out of a modern computer. We can deduce that this is happening because we have an interpreted language(GDScript) that’s going through a bunch of layers of indirection(through a VM) to do some simple instructions.
I won’t go into the details of why compiled languages are better. A high level overview of why compiled languages are faster:
- levels of indirection in interpreted languages that multiply the number of instructions that need to be run
- compiler optimizations that might not exist in interpreted languages
- the levels of indirection that untyped code adds to the interpreter
All in all, when determining if you should write a piece of code in a faster language, I’ll leave you with this really useful heuristic:
Generally, compiled languages will give you a fantastic increase(1-2 orders of magnitude) in speed when you have tight loops of simple CPU-bound code, such as running fundamental algorithms(sorting, queues, graphs, ect) or crunching numbers.
So what can I do with my code?
Essentially I took the priority queue and A* algorithm that I wrote in GDScript, and converted it to C++. that’s because the priority queue is a simple algorithm that has been optimized the hell out of in C++, and the A* algorithm is a simple tight loop that could be run in a few instructions.
How this actually shook out is GDScript has a native implementation of A* already written(https://docs.godotengine.org/en/stable/classes/class_astar2d.html ) Unfortunately (and this is why I didn’t use it originally), when determining the “cost” between two nodes, it calculates the cost between two nodes as the euclidean distance between them; that’s fine for most use cases, but because our train network is made up of curving tracks, the distance between junctions in our network won’t be the euclidean distance. This means we have to essentially keep track of our graph and its edge costs on our own. Luckily, we’re able to override the cost() function in this native implementation: https://docs.godotengine.org/en/stable/classes/class_astar2d.html#class-astar2d-private-method-compute-cost.
And so that’s what I did – I stored edge costs in GDScript and and used the Astar2D class for it’s A* implementation. The priority queue and search algorithm were therefore written in native C++ via AStar2D. With this I saw a 10x increase in speed; you can see this if you take a look at the function “find_path_with_movement”:
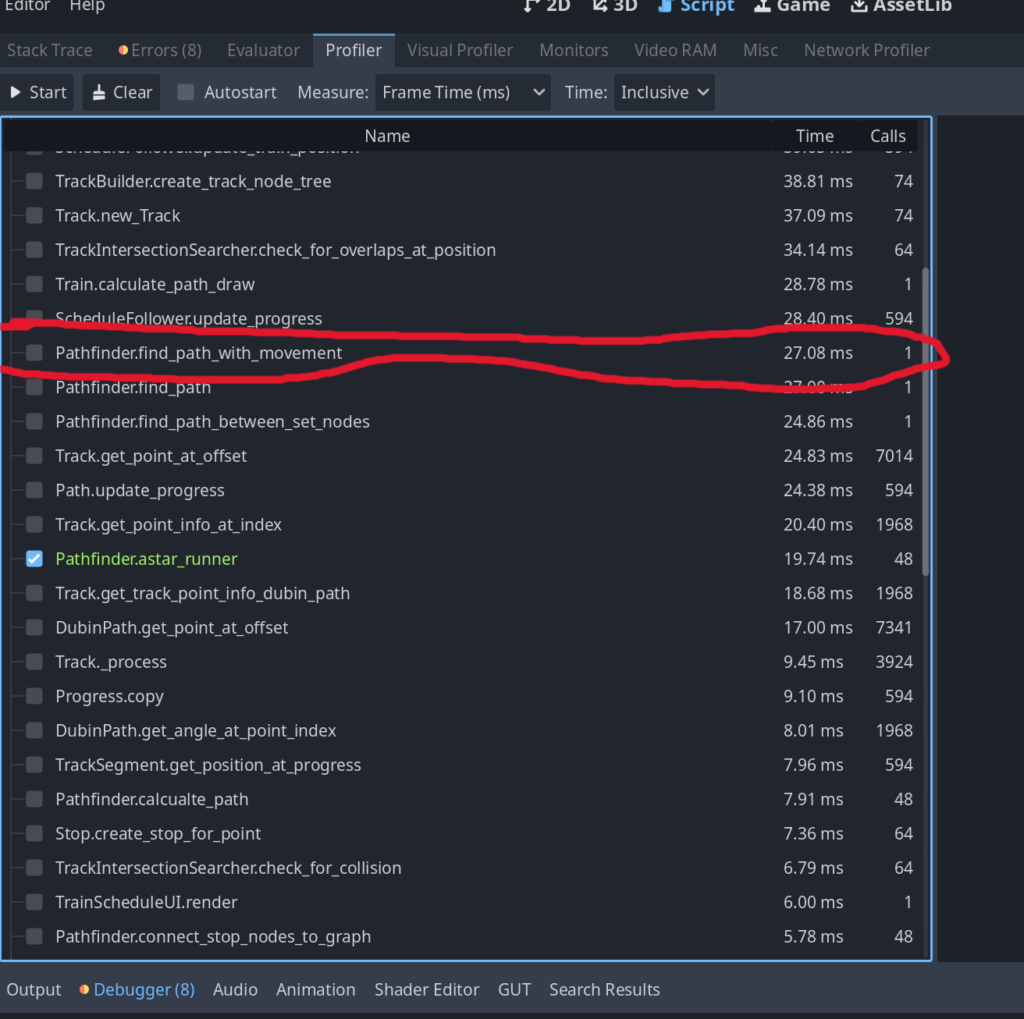
10x speed up – hurray!
How and when to optimize
However, this is still not ideal, since our compute_cost has to be called and interpreted from GDScript when we are looking at the cost of an edge. Still, having priority queue and 95% of the A* search algorithm heuristic written in C++ still gave me a 10x speedup. If the compute_cost function had also been called in C++, i would have expected another 10x speedup, because this compute_cost is called on every loop of our A* search function, and is guaranteed to be the slowest part of the algorithm.
So what would it take to convert the compute_cost algorithm from GDScript to C++? Well, there was no way to pass in the edge data to the AStarr2D class expect on a call-by-call-basis. If I wanted to pass in the whole object, one option would be to subclass Astar2D in C++, and then create the whole graph in C++, and then use that in subclass; but this required quite a bit of setup of GDNative plugins, setting up a C++ build toolchain, and converting my whole graph from GDscript to C++. This would have been a significant time-suck to bring something from 10s of ms to single-digit ms. Importantly though, this wouldn’t really have been a noticeable difference to the user – anything less than 30ms is hard to detect for a user.
In addition, and more importantly, the A* algorithm was no longer the slowest part of the pathfinding algorithm – drawing the lines on the screen was taking on the order of 30ms as well(see the function Train.calculate_path_draw, 4th from the top). Because of this, if I optimized the A* algorithm, we wouldn’t see any difference in user speed until I also optimized the drawing algorithm.
Therefore, I decided that what I wrote was “good enough”.
I talk about all this because I thought the thought process was interesting enough to share. To turn this thought process into something you can use in your own projects, ask yourself these 3 questions when determining if you want to optimize something:
Should I optimize?
What should I optimize?
Do optimization(then go back to step 1)

These two questions and action should be done in a loop, optimizing until you get to a level of optimization that is acceptable; and you should make calculated optimizations– don’t rewrite everything in C++ just because it’s fast; take on an optimization in chunks that are small, and that can contribute to the next level of optimization if the current step is not enough.
To apply this heuristic to what I did, here are the questions I asked when optimizing my pathfinding algorithm:
Should I optimize?
Yes, 400ms is slow and can be noticed by the user as a “freeze” in the game. Larger networks will annoyingly noticeable
What should I optimize?
Do the quick wins first that give you the most “bang for your buck” → there is a built in A* algorithm in godot (AStar2D) that we can leverage that is not much work to use and should give us a significant jump. It only requires us sync our graph/network in their class, so it’s not a lot of work.
After I completed this iteration, I saw a 10x speedup, to an average of 30ms per a run. Again I asked the two questions:
Should I optimize?
While 30ms is still slow for a search algorithm, it’s not really noticeable from a user’s standpoint(even with big graphs, it still hovers under 100ms).
What should I optimize?
Because the drawing of lines on the screen is taking the same amount of time as the pathfinding, I would have to optimize both parts of the code to see a speed increase; this is a lot of work, for again, not much benefit.
So in the end, I stopped after the “first” optimization. The code was still really slow for what it could be, but it was good enough.
Bonus: Typing makes things fast
Typing not only makes your code safe, but it makes it fast. In the documentation for typing in godot, they have the following:
The more typing information a GDScript has, the more optimized the compiled bytecode can be. For example, if my_var is untyped, the bytecode for my_var.some_member will need to go through several layers of indirection to figure out the type of my_var at runtime, and from there determine how to obtain some_member. This varies depending on whether my_var is a dictionary, a script, or a native class. If the type of my_var was known at compile time, the bytecode can directly call the type-specific method for obtaining a member. Similar optimizations are possible for my_var.some_func(). With untyped GDScript, the VM will need to resolve my_var’s type at runtime, then, depending on the type, use different methods to resolve the function and call it. When the function is fully resolved during static analysis, native function pointers or GDScript function objects can be compiled into the bytecode and directly called by the VM, removing several layers of indirection.
Typed code is safer code and faster code!
How fast? Well Cariad Eccleston over at bleep.blog ran some tests and come up with the fact it’s 30% faster to type your code in godot:
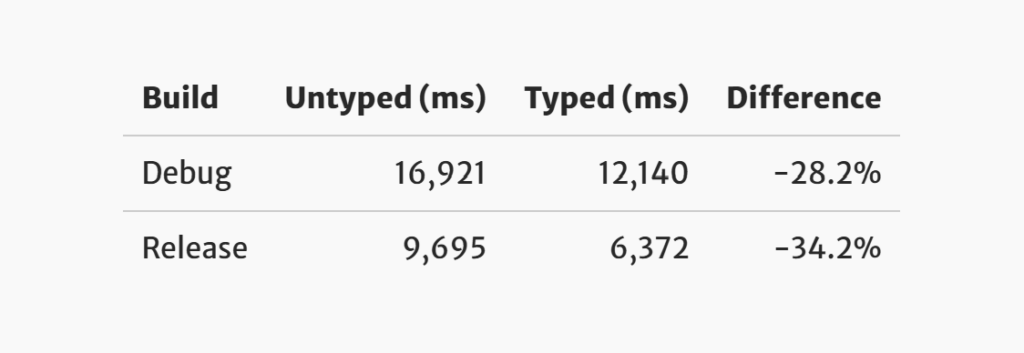
Credit: https://www.beep.blog/2024-02-14-gdscript-typing/
This is generally true of most typed interpreted languages – so when in doubt, type it out!